
![]() As you may know, I have been teaching BIO101 (and also the BIO102 Lab) to non-traditional students in an adult education program for about twelve years now. Every now and then I muse about it publicly on the blog (see this, this, this, this, this, this and this for a few short posts about various aspects of it – from the use of videos, to the use of a classroom blog, to the importance of Open Access so students can read primary literature). The quality of students in this program has steadily risen over the years, but I am still highly constrained with time: I have eight 4-hour meetings with the students over eight weeks. In this period I have to teach them all of biology they need for their non-science majors, plus leave enough time for each student to give a presentation (on the science of their favorite plant and animal) and for two exams. Thus I have to strip the lectures to the bare bones, and hope that those bare bones are what non-science majors really need to know: concepts rather than factoids, relationship with the rest of their lives rather than relationship with the other sciences. Thus I follow my lectures with videos and classroom discussions, and their homework consists of finding cool biology videos or articles and posting the links on the classroom blog for all to see. A couple of times I used malaria as a thread that connected all the topics – from cell biology to ecology to physiology to evolution. I think that worked well but it is hard to do. They also write a final paper on some aspect of physiology.
As you may know, I have been teaching BIO101 (and also the BIO102 Lab) to non-traditional students in an adult education program for about twelve years now. Every now and then I muse about it publicly on the blog (see this, this, this, this, this, this and this for a few short posts about various aspects of it – from the use of videos, to the use of a classroom blog, to the importance of Open Access so students can read primary literature). The quality of students in this program has steadily risen over the years, but I am still highly constrained with time: I have eight 4-hour meetings with the students over eight weeks. In this period I have to teach them all of biology they need for their non-science majors, plus leave enough time for each student to give a presentation (on the science of their favorite plant and animal) and for two exams. Thus I have to strip the lectures to the bare bones, and hope that those bare bones are what non-science majors really need to know: concepts rather than factoids, relationship with the rest of their lives rather than relationship with the other sciences. Thus I follow my lectures with videos and classroom discussions, and their homework consists of finding cool biology videos or articles and posting the links on the classroom blog for all to see. A couple of times I used malaria as a thread that connected all the topics – from cell biology to ecology to physiology to evolution. I think that worked well but it is hard to do. They also write a final paper on some aspect of physiology.
Another new development is that the administration has realized that most of the faculty have been with the school for many years. We are experienced, and apparently we know what we are doing. Thus they recently gave us much more freedom to design our own syllabus instead of following a pre-defined one, as long as the ultimate goals of the class remain the same. I am not exactly sure when am I teaching the BIO101 lectures again (late Fall, Spring?) but I want to start rethinking my class early. I am also worried that, since I am not actively doing research in the lab and thus not following the literature as closely, that some of the things I teach are now out-dated. Not that anyone can possibly keep up with all the advances in all the areas of Biology which is so huge, but at least big updates that affect teaching of introductory courses are stuff I need to know.
I need to catch up and upgrade my lecture notes. And what better way than crowdsource! So, over the new few weeks, I will re-post my old lecture notes (note that they are just intros – discussions and videos etc. follow them in the classroom) and will ask you to fact-check me. If I got something wrong or something is out of date, let me know (but don’t push just your own preferred hypothesis if a question is not yet settled – give me the entire controversy explanation instead). If something is glaringly missing, let me know. If something can be said in a nicer language – edit my sentences. If you are aware of cool images, articles, blog-posts, videos, podcasts, visualizations, animations, games, etc. that can be used to explain these basic concepts, let me know. And at the end, once we do this with all the lectures, let’s discuss the overall syllabus – is there a better way to organize all this material for such a fast-paced class.
Today, we continue with the cell – the basic processes of DNA transcription, RNA translation, and protein synthesis. See the previous lectures:
Biology and the Scientific Method
BIO101 – Cell Structure
Here is the third BIO101 lecture (from May 08, 2006). Again, I’d appreciate comments on the correctness as well as suggestions for improvement.
————————————————–
BIO101 – Bora Zivkovic – Lecture 1 – Part 3
The DNA code
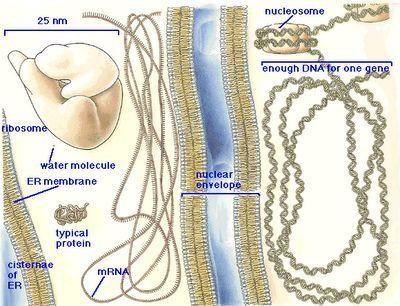
DNA is a long double-stranded molecule residing inside the nucleus of every cell. It is usually tightly coiled forming chromosomes in which it is protected by proteins.
Each of the two strands of the DNA molecule is a chain of smaller molecules. Each link in the chain is composed of one sugar molecule, one phosphate molecule and one nucleotide molecule. There are four types of nucleotides (or ‘bases’) in the DNA: adenine (A), thymine (T), guanine (G) and cytosine (C). The two strands of DNA are structured in such a way that an adenine on one strand is always attached to a thymine on the other strand, and the guanine of one strand is always bound to cytosine on the other strand. Thus, the two strands of the DNA molecule are mirror-images of each other.
The exact sequence of nucleotides of all of the DNA on all the chromosomes is the genome. Each cell in the body has exactly the same chromosomes and exactly the same genome (with some exceptions we will cover later).
A gene is a small portion of the genome – a sequence of nucleotides that is expressed together and codes for a single protein (polypeptide) molecule.
Cell uses the genes to synthesize proteins. This is a two-step process. The first step is transcription in which the sequence of one gene is replicated in an RNA molecule. The second step is translation in which the RNA molecule serves as a code for the formation of an amino-acid chain (a polypeptide).

Transcription
For a gene to be expressed, i.e., translated into RNA, that portion of the DNA has to be uncoiled and freed of the protective proteins. An enzyme, called DNA polymerase, “reads” the DNA (the sequence of bases on one of the two strands of the DNA molecule) and builds a single-stranded chain of the RNA molecule as a complementary, mirror-image sequence. Again, where there is a G in DNA, there will be C in the RNA and vice versa. Instead of thymine, RNA has uracil (U). Wherever in the DNA strand there is an A, there will be a U in the RNA, and wherever there is a T on the DNA molecule, there will be an A in the RNA.
Once the whole gene (100s to 10,000s of bases in a row) is transcribed, the RNA molecule detaches. The RNA (called messenger RNA or mRNA) may be further modified by addition of more A bases at its tail, by addition of other small molecules to some of the nucleotides and by excision of some portions (introns) out of the chain. The removal of introns (the non-coding regions) and putting together the remaining segments – exons – into a single chain again, is called RNA splicing. RNA splicing allows for one gene to code for multiple related kinds of proteins, as alternative patterns of splicing may be controlled by various factors in the cell.
Unlike DNA, the mRNA molecule is capable of exiting the nucleus through the pores in the nuclear membrane. It enters the endoplasmatic reticulum and attaches itself to one of the membranes in the rough ER.
Translation
Three types of RNA are involved in the translation process: mRNA which carries the genetic code, rRNA which aids in the formation of the ribosome, and tRNA which brings individual amino-acids to the ribosome. Translation is controlled by various enzymes that recognize specific nucleotide sequences.
The genetic sequence (nucleotide sequence of a gene) translates into a polypeptide (amino-acid sequence of a protein) in a 3-to-1 fashion. Three nuclotides in a row code for one amino-acid. There are a total of 20 amino-acids used to build all proteins in our bodies. Some amino-acids are coded by a single triplet code, or codon. Other amino-acids may be coded by several different RNA sequences. There is also a START sequence (coding for fMet) and a STOP sequence that does not code for any amino-acid. The genetic code is (almost) universal. Except for a few microorganisms, all of life uses the same genetic code – the same triplets of nucleotides code for the same amino-acids.

When the ribosome is assembled around a molecule of mRNA, the translation begins with the reading of the first triplet. Small tRNA molecules bring in the individual amino-acids and attach them to the mRNA, as well as to each other, forming a chain of amino-acids. When a stop signal is reached, the entire complex disassociates. The ribosome, the mRNA, the tRNAs and the enzymes are then either degraded or re-used for another translational event.
Protein synthesis – post-translational modifications
Translation of the DNA/RNA code into a sequence of amino-acids is just the beginning of the process of protein synthesis.
The exact sequence of amino-acids in a polypeptide chain is the primary structure of the protein.
As different amino-acids are molecules of somewhat different shapes, sizes and electrical polarities, they react with each other. The attractive and repulsive forces between amino-acids cause the chain to fold in various ways. The three-dimensional shape of the polypeptide chain due to the chemical properties of its component amino-acids is called the secondary structure of the protein.
Enzymes called chaperonins further modify the three-dimensional structure of the protein by folding it in particular ways. The 3D structure of a protein is its most important property as the functionality of a protein depends on its shape – it can react with other molecules only if the two molecules fit into each other like a key and a lock. The 3D structure of the fully folded protein is its tertiary structure.
Prions, the causes of such diseases as Mad Cow Disease, Scrapie and Kreutzfeld-Jacob disease, are proteins. The primary and secondary structure of the prion is almost identical to the normally expressed proteins in our brain cells, but the tertiary structure is different – they are folded into different shapes. When a prion enters a healthy brain cell, it is capable of denaturing (unwinding) the native protein and then reshaping it in the same shape as the prion. Thus one prion molecule makes two – those two go on and make four, those four make eight, and so on, until the whole brain is just one liquifiied spongy mass.
Another aspect of the tertiary structure of the protein is addition of small molecules to the chain. For instance, phosphate groups may be attached to the protein (giving it additional energy). Also, short chains of sugars are usually bound to the tail-end of the protein. These sugar chains serve as “ZIP-code tags” for the protein, informing carrier molecules exactly where in the cell this protein needs to be carried to (usually within vesicles that bud off the Rough Enodplasmic Reticulum or the Golgi apparatus). The elements of the cytoskeleton are used as conduits (“elevators and escalators”) to shuttle proteins to where in the cell they are needed.
Many proteins are composed of more than one polypeptide chain. For instance, hemoglobin is formed by binding together four subunits. Each subunit also has a heme molecule attached to it, and an ion of iron attached to the heme (this iron is where oxygen binds to hemogolobin). This larger, more complex structure of the protein is its quaternary structure.
See animations:
Previously in this series:










{kind=link}
{kind=link}